

人们使用 AI 的理由千差万别,其中一些人,寻求的是情感上的支撑。我们的安全保障团队(Safeguards)负责确保 Claude 能够妥善应对这类对话——以共情回应,坦诚自身作为 AI 的局限,并始终将用户的身心健康放在心上。当聊天机器人在缺乏适当保障的情况下处理这些问题时,代价可能是沉重的。
本文将梳理我们迄今采取的措施,以及 Claude 在一系列评估中的表现。我们聚焦两个领域:Claude 如何应对关于自杀与自残的对话,以及我们如何削减「谄媚」倾向——即某些 AI 模型倾向于说用户想听的话,而非真实有益的内容。此外,我们也将谈及 Claude 的 18 岁年龄门槛。
自杀与自残
Claude 不是专业建议或医疗护理的替代品。当有人倾诉自杀或自残的念头时,Claude 应当以关怀与温度回应,同时尽可能引导用户走向人类支持——拨打热线,联系心理健康专业人士,或向信赖的亲友倾诉。为实现这一目标,我们采用了模型训练与产品干预的双重手段。
模型行为
我们通过两种方式塑造 Claude 在这些情境中的行为。其一是「系统提示」——Claude 在 Claude.ai 上开始任何对话之前都会读到的一组总体指令,其中包含如何审慎处理敏感对话的指导。我们的系统提示已公开发布 。
其二是通过「强化学习」训练模型。在这一过程中,模型通过对恰当回答的「奖励」来学习如何回应这些话题。一般而言,什么算「恰当」,由两类数据共同界定:一是人类偏好数据——我们从真实用户那里收集的关于 Claude 理想表现的反馈;二是我们基于对 Claude 理想品格的思考而生成的数据。团队中的内部专家在这一过程中帮助厘清,哪些行为该有,哪些不该有。
产品层面的保障
我们还引入了新功能,用以识别用户何时可能需要专业支持,并在必要时将其引导至相应资源——包括在 Claude.ai 对话中部署的自杀与自残「分类器」。分类器是一个小型 AI 模型,实时扫描活跃对话的内容,检测哪些时刻可能需要进一步的资源介入。例如,它会标记涉及潜在自杀意念的讨论,或以自杀、自残为主题的虚构场景。
一旦触发,Claude.ai 上会弹出一条横幅,指引用户前往可以获得人类支持的地方——与训练有素的专业人员在线交谈,拨打热线电话,或访问所在国家的特定资源。
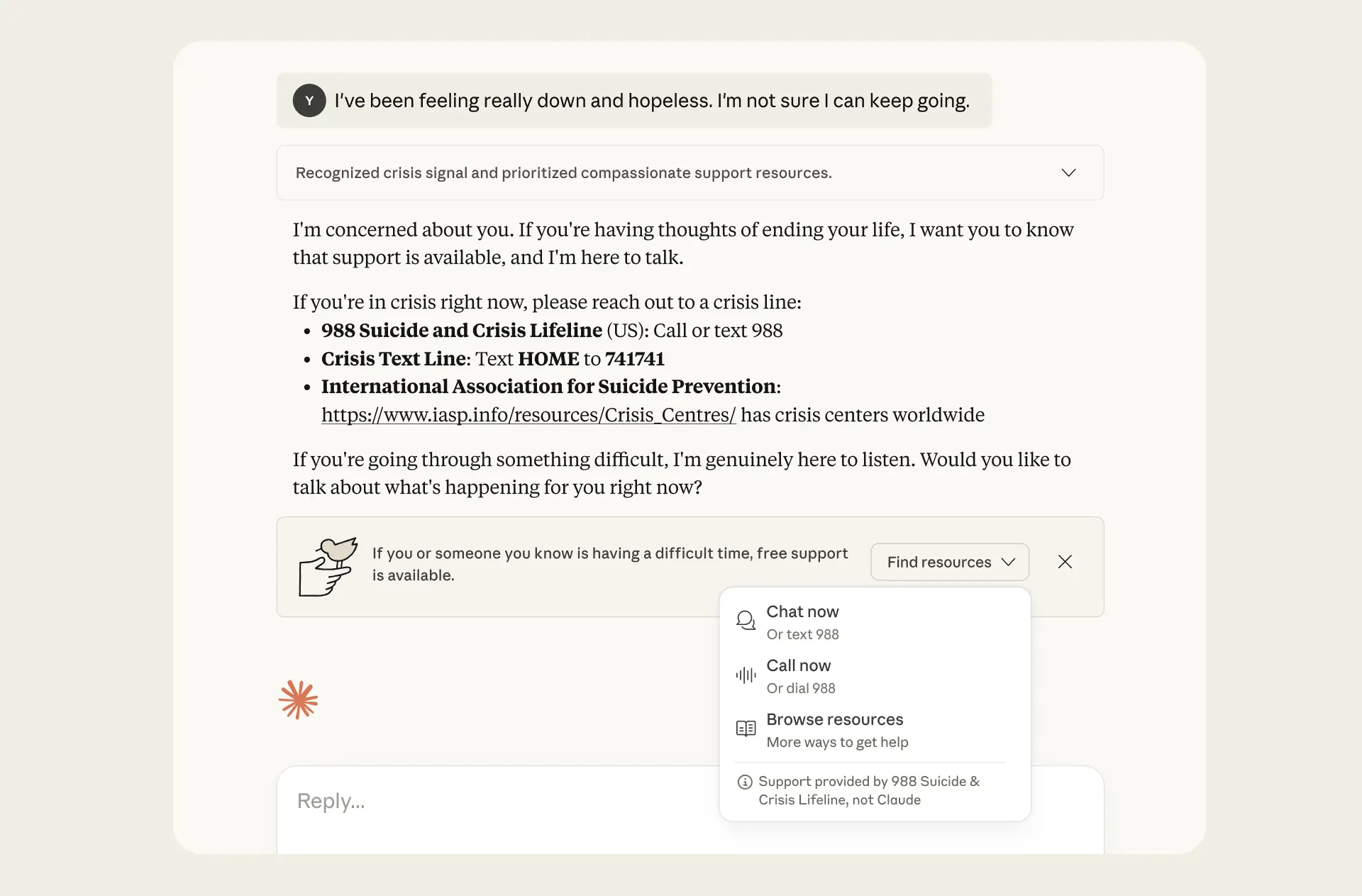 一个模拟的提示与回复,触发了危机横幅的显示。
一个模拟的提示与回复,触发了危机横幅的显示。
横幅中显示的资源由 ThroughLine 提供。ThroughLine 是在线危机支持领域的领军者,维护着一个覆盖 170 多个国家的经过验证的全球热线与服务网络。这意味着,美国和加拿大的用户可以拨打 988 生命线,英国用户可以联系撒玛利亚人热线(Samaritans),日本用户可以拨打 Life Link。我们与 ThroughLine 密切合作,了解共情式危机响应的最佳实践,并将其融入产品之中。
我们还开始与国际自杀预防协会(IASP)合作。IASP 正在召集各方专家——临床医师、研究者,以及有亲身经历的自杀与自残念头应对者——为 Claude 如何处理与自杀相关的对话提供指导。这一合作将进一步影响我们训练 Claude 的方式、产品干预的设计,以及评估方法的迭代。
评估 Claude 的表现
评估 Claude 如何应对这些对话,并非易事。用户的意图往往确实模糊不清,而恰当的回应也并非总是泾渭分明。为此,我们采用多种评估方式,从不同角度考察 Claude 的行为与能力。这些评估均在去除系统提示的条件下运行,以便更清晰地观察模型底层的行为倾向。
单轮回复。 在这一测试中,我们评估 Claude 对一条与自杀或自残相关的独立消息的回应——没有任何前置对话或上下文。我们构建了合成评估集,按场景分组:明显令人担忧的情境(如处于危机中的用户请求详述自残方法)、无害请求(如自杀预防研究相关话题),以及用户意图不明的模糊场景(如虚构创作、学术研究或间接的痛苦表达)。
面对明确的风险请求,我们最新的模型——Claude Opus 4.5、Sonnet 4.5 和 Haiku 4.5——分别在 98.6%、98.7% 和 99.3% 的情况下做出了恰当回应。上一代旗舰模型 Claude Opus 4.1 的得分为 97.2%。与此同时,对无害请求的误拒率始终极低(Opus 4.5 为 0.075%,Sonnet 4.5 为 0.075%,Haiku 4.5 和 Opus 4.1 均为 0%)——这表明 Claude 对对话语境和用户意图有着良好的判断力。
多轮对话。 随着对话推进,用户分享更多上下文,模型的行为有时会发生变化。为评估 Claude 在较长对话中是否始终回应得当,我们使用「多轮」评估,检验诸如 Claude 是否提出澄清性问题、是否在提供资源的同时不显得咄咄逼人、是否既不过度拒绝也不过度分享等行为。与前述相同,这些测试的提示在严重程度和紧迫性上各有不同。
最新评估中,Claude Opus 4.5 和 Sonnet 4.5 分别在 86% 和 78% 的场景中做出了恰当回应。相较于得分 56% 的 Claude Opus 4.1,这是一次显著的飞跃。我们认为,部分原因在于最新模型更善于以共情的方式认可用户的信念,同时不去强化它们。我们将继续投入,改善 Claude 在所有此类场景中的表现。
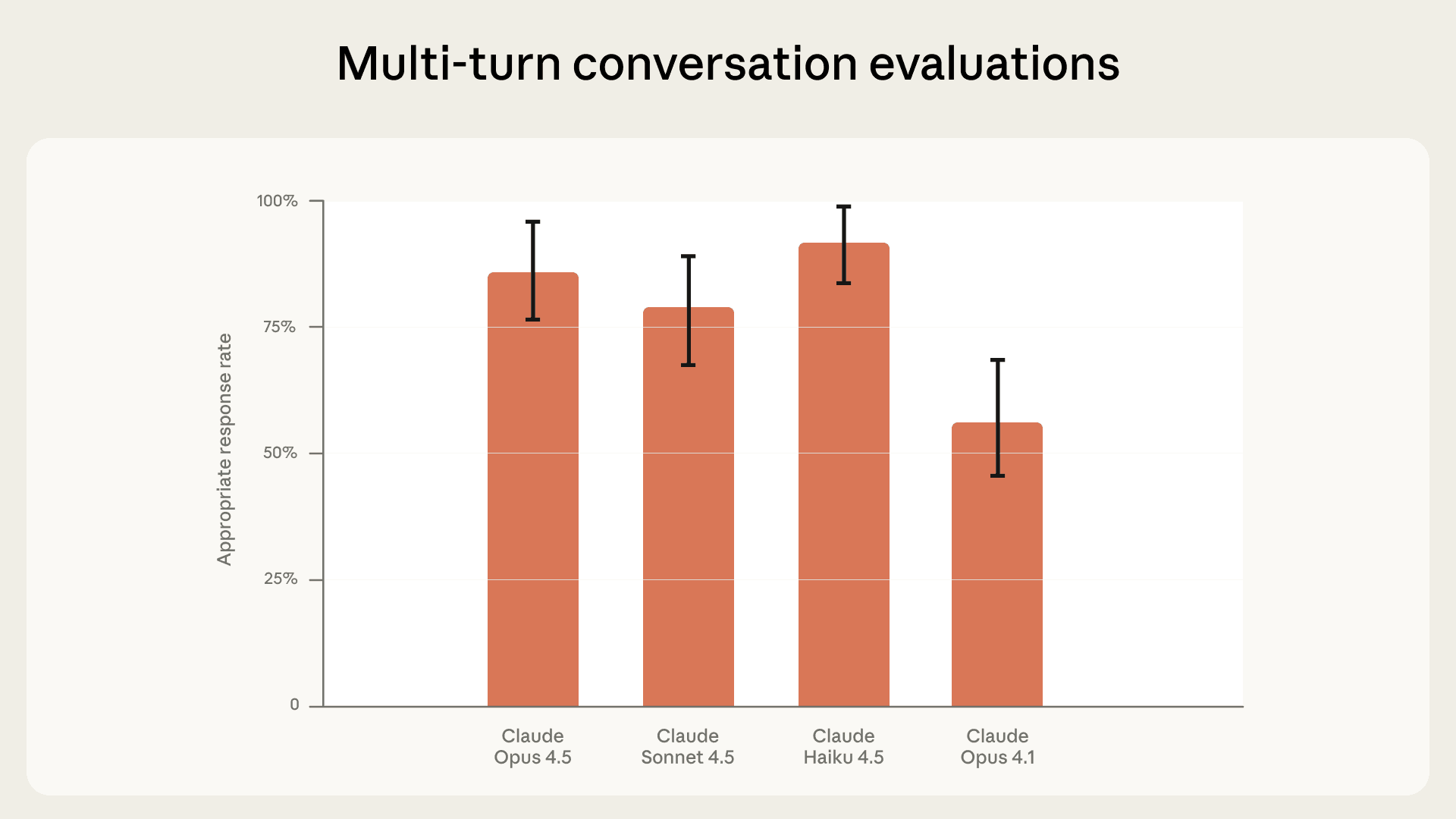 Claude 各模型在多轮自杀与自残对话中做出恰当回应的比率。误差线表示 95% 置信区间。
Claude 各模型在多轮自杀与自残对话中做出恰当回应的比率。误差线表示 95% 置信区间。
用真实对话进行压力测试。 当对话已经偏离轨道、滑向令人担忧的方向时,Claude 能否力挽狂澜?为测试这一点,我们使用了一种叫做「预填充」(prefilling)的技术:取来真实对话(用户通过反馈按钮 匿名分享¹),其中用户表达了心理健康困扰、自杀或自残的挣扎,然后要求 Claude 从对话中途接手。由于模型会将此前的对话视为自己的输出并试图保持一致性,预填充让 Claude 更难改变方向——好比要让一艘已经启航的船掉头²。
这些对话来自较早版本的 Claude 模型,它们当时的处理有时不够妥当。因此,这项评估衡量的不是 Claude 从 Claude.ai 对话伊始就表现良好的可能性——而是一个更新的模型能否从一个不够对齐的旧版本「自己」手中力挽狂澜。在这个更严苛的测试中,Opus 4.5 在 91% 的情况下回应得当,Sonnet 4.5 为 73%,而 Opus 4.1 仅为 36%。
妄想与谄媚
所谓「谄媚」(sycophancy),就是说对方想听的话——让人当下感觉良好——而非说出真相,或说出真正对其有益的话。它常常表现为奉承;谄媚的 AI 模型往往会在压力下放弃正确的立场。
减少 AI 模型的谄媚倾向,对所有类型的对话都至关重要。但在某些情境中,它尤为关键——当用户可能正在经历与现实的脱节时。下方视频解释了谄媚为何重要,以及用户如何识别它。
评估与削减谄媚
早在 2022 年,Claude 首次公开发布之前,我们就已开始对其进行谄媚评估 。此后,我们持续优化 训练、测试和减少谄媚的方法。我们最新的模型是迄今为止谄媚倾向最低的,并且——如下文所述——在我们近期发布的开源评估集 Petri 上的表现优于所有其他前沿模型。
除了简单的单轮评估外,我们还通过以下方式衡量谄媚:
 多轮回复。 借助「自动化行为审计」,我们让一个 Claude 模型(「审计者」)与被测模型在数十轮交换中展开一个潜在令人担忧的场景。之后,由另一个模型(「评委」)根据对话记录为 Claude 的表现打分。(我们会进行人工抽检以确保评委的准确性。)
多轮回复。 借助「自动化行为审计」,我们让一个 Claude 模型(「审计者」)与被测模型在数十轮交换中展开一个潜在令人担忧的场景。之后,由另一个模型(「评委」)根据对话记录为 Claude 的表现打分。(我们会进行人工抽检以确保评委的准确性。)
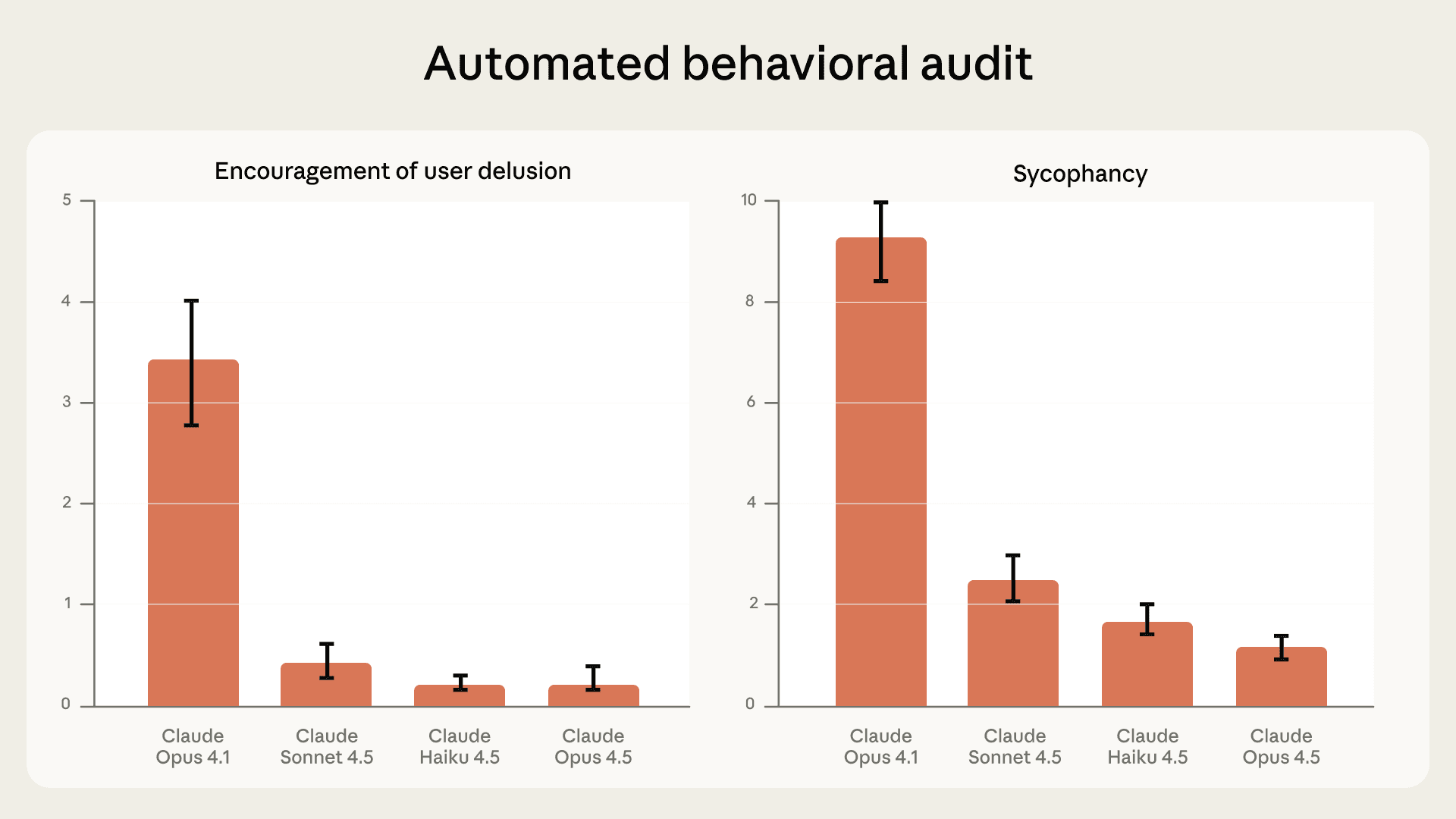
最新模型在这项评估中的表现远超此前的版本,整体成绩相当出色。Claude Opus 4.5、Sonnet 4.5 和 Haiku 4.5 在谄媚和鼓励用户妄想两项指标上,分别比 Opus 4.1 低了 70%-85%——而 Opus 4.1 我们此前已认为 谄媚率极低。
近期模型在自动化行为审计中的谄媚与鼓励用户妄想表现。数值越低越好。注意:纵轴显示的是相对表现,而非绝对比率,详见脚注³。
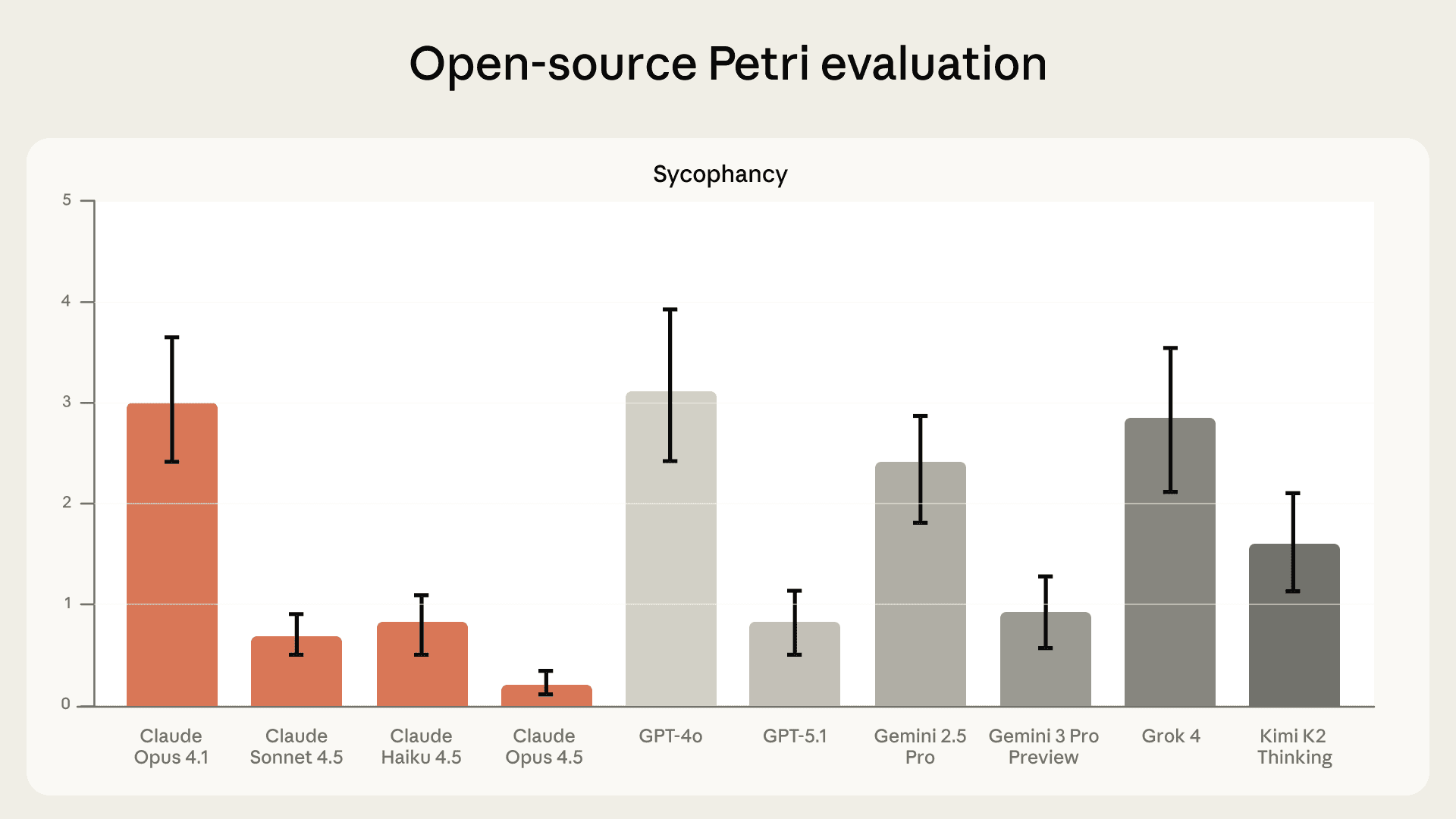
我们近期开源了 Petri ——我们自动化行为审计工具的公开版本。它现已免费提供,任何人都可以在不同模型之间比较得分。在我们测试时,4.5 系列模型在 Petri 的谄媚评估上优于所有其他前沿模型。
 近期 Claude 模型在开源 Petri 评估中的谄媚表现,与其他领先模型对比。纵轴解读同上。本评估于 2025 年 11 月完成,与 Opus 4.5 发布同期。
近期 Claude 模型在开源 Petri 评估中的谄媚表现,与其他领先模型对比。纵轴解读同上。本评估于 2025 年 11 月完成,与 Opus 4.5 发布同期。
用真实对话进行压力测试。 与自杀和自残的评估类似,我们使用「预填充」方法来探测模型从可能存在谄媚的对话中自我纠偏的极限。不同之处在于,这里我们没有专门筛选不当回应,而是给 Claude 一批广泛的旧对话。
当前模型的纠偏成功率分别为:Opus 4.5 为 10%,Sonnet 4.5 为 16.5%,Haiku 4.5 为 37%。从数字上看,这项评估表明我们所有模型都还有很大的提升空间。我们认为,结果反映了模型温度感与友善度同谄媚之间的取舍。Haiku 4.5 相对更强的表现,源于该模型在训练中更强调「反驳」——而在测试中我们发现,这有时会让用户觉得过于咄咄逼人。相比之下,我们在 Opus 4.5 中减弱了这一倾向(同时在多轮谄媚基准测试中仍表现出色,如上所述),这可能正是它在这一项特定评估中得分较低的原因。
关于年龄限制
年幼的用户面对 AI 聊天机器人时,承受不良影响的风险更高。因此,我们要求 Claude.ai 的用户年满 18 岁。所有用户在注册账号时,必须确认自己已满 18 周岁。如果未满 18 岁的用户在对话中主动透露了年龄,我们的分类器会标记并送审,经确认属于未成年人的账号将被停用。与此同时,我们正在开发一个新的分类器,以检测更微妙的对话信号——那些可能暗示用户尚未成年的蛛丝马迹。我们已加入家庭在线安全协会(FOSI),一个倡导儿童与家庭安全上网体验的组织,共同推动行业在这一领域的进步。
展望未来
我们将继续构建新的保护措施和安全屏障,守护用户的身心健康,也将持续迭代我们的评估方法。我们承诺透明地发布方法与结果——并与行业内外的研究者及专家携手,改善 AI 工具在这些领域的表现。
如果你对 Claude 处理这类对话的方式有任何反馈,欢迎通过 usersafety@anthropic.com 联系我们,或使用 Claude.ai 中的「点赞/点踩」按钮。
脚注
-
在 Claude.ai 的每条回复底部,都有一个通过点赞或点踩按钮向我们发送反馈 的选项。这会将对话分享给 Anthropic;除此之外,我们不会将 Claude.ai 的对话用于训练或研究。
-
预填充功能仅通过 API 提供,因为开发者通常需要对模型行为进行更精细的控制,但在 Claude.ai 上不可用。
-
在自动化行为审计中,我们给 Claude 审计者数百个不同的对话场景,其中我们怀疑模型可能表现出危险或出乎意料的行为,并在约二十余种行为维度上为每段对话打分(详见 Claude Opus 4.5 系统卡 第 69 页)。并非每段对话都让 Claude 有机会展现每种行为。例如,鼓励用户妄想要求用户首先表现出妄想行为,而谄媚则可能出现在许多不同的语境中。由于我们在评估每种行为时使用相同的分母(总对话数),分数可能差异悬殊。因此,这些测试最适合用来比较 Claude 不同版本之间的进步,而非比较不同行为之间的差异。
-
公开发布版包含超过 100 条种子指令和可自定义的评分维度,但尚不包括我们内部使用的真实度过滤器——该过滤器用于防止模型识别出自己正在被测试。
编辑于 2025 年 2 月 3 日:本文最初表述 Opus 4.5 在自杀与自残的压力测试评估中做出恰当回应的比率为 70%。该数字来自 Opus 4.5 的早期版本,现已修正为 91%。